Maurizio Colleluori looks at the five major reasons behind data lake failure, pinpointing what businesses need to do to get back on the path to success...
Luca Naso's insight:
Why Data Lake projects may fail? The article reports 5 reasons, that I would group into 3:
1. Lack of Experience (both skilled employees and experienced vendors)
This definition explains the meaning of data governance, which is the management of the availability, usability, integrity and security of enterprise data.
Luca Naso's insight:
Big Data won't take your Company that far if you don't have a good Data Governance system in place. This article lays the foundations of the topic.
I would reframe the following as the 4 pillars:
1. Data Stewardship
2. Set of standards and procedures (to guarantee data quality)
3. Data governance team (to implement bullet 3)
4. Master Data Management (to establish a master reference to ensure consistent use of data across the organization)
Cloud computing makes it easier these days to implement a business intelligence initiative, but look before you leap.
Luca Naso's insight:
Today, technologies have advanced a great deal and made many things easier. This does not mean that implementing and doing advanced analytics is a no brainer!
Hadoop and Apache Spark are both big-data frameworks, but they don't really serve the same purposes.
Luca Naso's insight:
In my opinion, Spark should NOT be compared with Hadoop but with MapReduce. However, people usually compare Hadoop and Spark (probably because they are buzzwords).
5 things to keep in mind:
1. They do different things -
Hadoop is a distributed data infrastructure (HDFS),
Spark is a data-processing tool.
2. Hadoop is more complete -
Hadoop also includes a data-processing tool (MapReduce),
Spark does not have its own filesystem and needs to be integrated with some.
3. Spark is (much) faster -
MapReduce operates in step;
Spark operates in one shot (because it is in-memory).
4. Speed is not always what you need -
For batch processing you do not need Spark's high velocity;
Common applications for Spark are those requiring real-time analysis.
How industries like banking, healthcare, education, manufacturing, Insurance, retail, etc. are using big data.
Luca Naso's insight:
There is a substantial spending on big data, with more than 75% of companies (from different industries) investing in big data in the next two years.
Each industry vertical has its own challenges and solutions. Here is a great article and infographics by simplilearn that describe for 10 verticals both main challenges and applications.
Businesses now collect so much data that the resulting insights can not only describe customer behaviour in the present, but predict what it will look like in the future as well.
Luca Naso's insight:
Predictive analytics, or the ability to make accurate predictions, is based on good data and good algorithms. Every sensible data scientist knows this. It's good to see that this knowledge is spreading. Data alone, no matter how big, cannot give the right answers.
I believe that useful predictive analytics gives *accurate* predictions, not *exact* predictions. Predictive analytics which gives exact predictions is used in Science, not in Business.
Predictive analytics, or the ability to make accurate predictions, is based on good data and good algorithms. Every sensible data scientist knows this. It's good to see that this knowledge is spreading. Data alone, no matter how big, cannot give the right answers.
I believe that useful predictive analytics gives *accurate* predictions, not *exact* predictions. Predictive analytics which gives exact predictions is used in Science, not in Business.
New products, new technologies and an acquisition announced over the last two weeks may be small items on their own, but they add up to an important shift in the Big Data space.
Luca Naso's insight:
1. IBM is improving its cloud-based elastic data warehouse;
2. Cloudera announces Ibis: a project for letting data-scientists use Python directly on Hadoop;
3. Amazon is making Elastic MapReduce almost plug-and-play.
What's especially interesting about all of these announcements is that they are signs of a maturing market. No one's introducing a brand new data processing engine. Instead, IBM is improving, acquiring and competing; Amazon is streamlining; Cloudera is re-platforming; and Apache NiFi is integrating.
I am taking a few courses in Data Analytics. My friend @laurakenyon told me it is a huge deal for marketers now. Indeed ROI and understanding metrics are fundamentals of the marketing profession.
1. IBM is improving its cloud-based elastic data warehouse;
2. Cloudera announces Ibis: a project for letting data-scientists use Python directly on Hadoop;
3. Amazon is making Elastic MapReduce almost plug-and-play.
What's especially interesting about all of these announcements is that they are signs of a maturing market. No one's introducing a brand new data processing engine. Instead, IBM is improving, acquiring and competing; Amazon is streamlining; Cloudera is re-platforming; and Apache NiFi is integrating.
The Internet of Things is the 3rd wave of internet that is transforming the ways in which we live and work. Therefore, it has to involve the physical world.
Luca Naso's insight:
"Automation" is an important part of the equation. Internet of Things is not about moving the switches from the wall into the device (smartphone or tablet), but to remove them all!
We are at a stage where software has a concrete opportunity to reinvent the hardware.
Security is another important part of the equation. And it only happens if you include it in your design. This requires time, people, resource and money.
Even more, security and easy of use are on different part of the balance. There is a trade-off between "plug and play" and security, and it is not yet clear how to achieve the best balance.
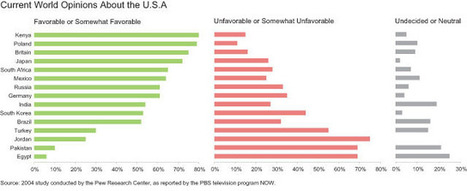
Switzerland, Sweden, the United States, the United Kingdom and Singapore are the world’s most innovative economies in 2023, according to WIPO’s Global Innovation Index (GII), as a group of middle-income economies have emerged over the past decade as the fastest climbers of the ranking.
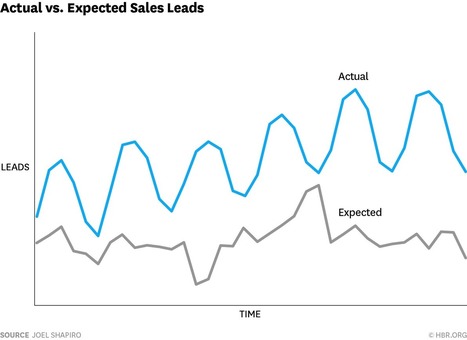
Slick graphics can make useless information seem important.
Luca Naso's insight:
Dashboards are a powerful tool, but if not used properly they can harm you more than you think. Creating an effective Visualisation is the result of a lot of work and knowledge, both of the data and of the business. Here are 3 most dangerous mistakes:
1. The Importance trap (misjudging what's relevant)
2. The Context Trap
3. The Causality trap (especially true with Big Data)
Avoid the data swamp! Use modern cloud based DWaaS (Snowflake) and the leading-edge Data Integration tool (Talend) to build a Governed Data Lake.
Luca Naso's insight:
When building a Data Lake it is important to make it "Governed", or it will become a Data Swamp, i.e. a messy place that collects all the data, and where it is difficult, if not impossible, to extract value.
The article clarifies this point quite well, in addition, it proposes an architecture based on Talend.
This year begins the shift of big data away from a topic unto itself, and toward standard practices
Luca Naso's insight:
My 3 takeaways from 2015 Gartner's research on Big Data:
1. Big Data solutions and technologies are becoming mainstream;
2. Big Data is mainly used for enhancing customer experience;
3. Business Leaders are as active as CIO/CTO in launching Big Data projects.
Organisations are overwhelmingly targeting enhanced customer experience as the primary goal of big data projects (64 percent). Process efficiency and more-targeted marketing are now tied at 47 percent. As data breaches continue to make headlines, enhanced security capabilities saw the largest increase, from 15 percent to 23 percent.
Last year, 37 percent of big data projects were initiated by the CIO, while 25 percent were initiated by business unit heads. In 2015, the roles are nearly tied, at 32 percent and 31 percent, respectively.
Big Data is the new buzzword as far as mass operations, iterations and manipulations are concerned. The data becomes an asset that requires cost-effective innovations ...
Luca Naso's insight:
How is Big Data changing the banks business? And how this can add value for customers?
Today it is imperative to use machine learning for detecting frauds and mitigating risks. The next step should be solidifying the relationship with clients, by offering what they really need, not what the bank wants to sell.
The 6 uses of Big Data in banking
1. Increase efficiency - shorten the time to get information from db
2. Reduce cost - in maintaining the data infrastructure
3. Prevent fraud - self-evident
4. Accountability - better evaluation of clients' risk
5. New revenue streams - the more you know the more you can offer
6. Client satisfaction - by offering a better customer experience
With Big Data solutions spawning the requirement for applications focusing on Data Analytics, HANA’s capabilities are serving as the perfect partner for Hadoop. Read this article to know more about this perfect combination
Luca Naso's insight:
SAP HANA and Hadoop are very different, that's why they could be a good combination in terms of complementing each other.
For example, SAP HANA is in-memory and uses predefined schema, while Hadoop is on disk and has no schema.
A scalable column-oriented database management for real-time analytics (SAP HANA) meets a technology platform that supports any kind of data for analyzing massive amount of data (Hadoop).
Which accounts should I follow on Twitter to stay up to date with Big Data? Here is the answer from a new algorithm.
Luca Naso's insight:
After screening the whole Twitter looking for #BigData posts, counting tweets, retweets, favourites and followers, the article reports the top50 accounts that best performed in the month of July 2015.
Here are the top5:
1. KPMG (Score = 100.0%)
2. World Economic Forum (83.8%)
3. CloudEXPO ® (57.6%)
4. UN Development (45.4%)
5. Popular Science (41.4%)
Following them could be a wise idea for those who want to know more about the field!
After screening the whole Twitter looking for #BigData posts, counting tweets, retweets, favourites and followers, the article reports the top50 accounts that best performed in the month of July 2015.
Here are the top5:
1. KPMG (Score = 100.0%)
2. World Economic Forum (83.8%)
3. CloudEXPO ® (57.6%)
4. UN Development (45.4%)
5. Popular Science (41.4%)
Following them could be a wise idea for those who want to know more about the field!
After screening the whole Twitter looking for #BigData posts, counting tweets, retweets, favourites and followers, the article reports the top50 accounts that best performed in the month of July 2015.
Here are the top5:
1. KPMG (Score = 100.0%)
2. World Economic Forum (83.8%)
3. CloudEXPO ® (57.6%)
4. UN Development (45.4%)
5. Popular Science (41.4%)
Following them could be a wise idea for those who want to know more about the field!
Hiring the best is hard because there's so much human variation. Amazon's Anurag Gupta shares a system that always raises the bar.
Luca Naso's insight:
"Good intentions don't work, but a repeatable, measurable and improvable process can" by Anurag Gupta, at Amazon.
Nobody wants to hire the wrong person and nobody wants to work for the wrong company. By following processes, it is possible to reduce the probabilities for things like these to happen.
1. Raise the bar, steadily and honestly;
2. Build a hiring funnel. By consistently repeating a process, you improve it. Do yourself a favour: filter candidates at each step;
3. Don't go easy on culture. This is the hardest to standardize, and yet it's one of the main reason why employee will not stay.
To get content containing either thought or leadership enter:
To get content containing both thought and leadership enter:
To get content containing the expression thought leadership enter:
You can enter several keywords and you can refine them whenever you want. Our suggestion engine uses more signals but entering a few keywords here will rapidly give you great content to curate.

 Your new post is loading...
Your new post is loading...