




Though tablets and ebook readers are now mainstream, the revolution in the way they display content – and how that content will be generated dynamically – is yet to come.
With the introduction of analytics into the visual design of written content, we are on the cusp of an era of incredible evolution: one where the design of information changes in real time in response to data about the readers consuming it. New technologies from Amazon, Apple, Google, WordPress and Tumblr already provide a preview of Intelligent Content. In essence, it won’t be long before the media we consume knows us better than we know ourselves.
Content that reacts to being read
Around 1952, computer scientist Grace Hopper introduced new thinking about compilers –machine-independent software that would translate code written in human language into computer friendly binary ones. John Von Nuemann took Dr. Hopper’s work to a new level in his unfinished masterpiece “The Computer and the Brain,” which theorized that massive versions of compilers would eventually result in computers so intelligent that no human mind could keep up with them.
In a way, books and magazines of the future will act as sort of human compilers, translating your reading desires into pure machine language that tells the publisher how to present the material for faster and more pleasurable absorption. It’s difficult to comprehend what these experiences will be like once machines themselves begin creating material for humans. The content itself will be designed to gather information about the reader, mash it up with data about others interested in related subjects, authors, or publishers, then decide what content to present to you next. This is what we mean by Intelligent Content

 Your new post is loading...
Your new post is loading...





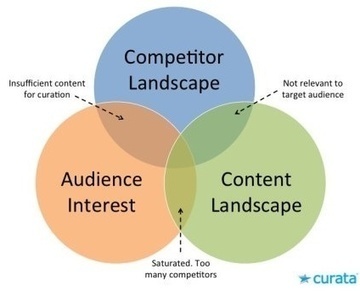









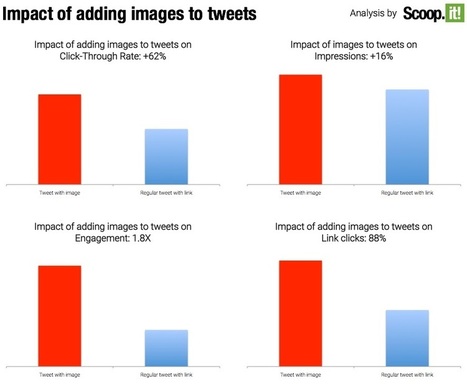


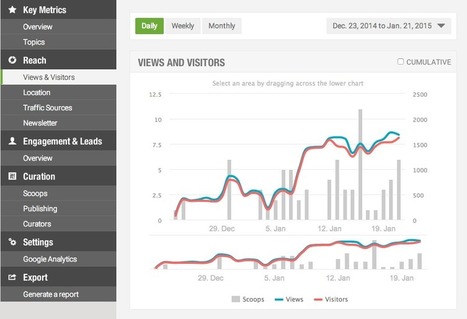






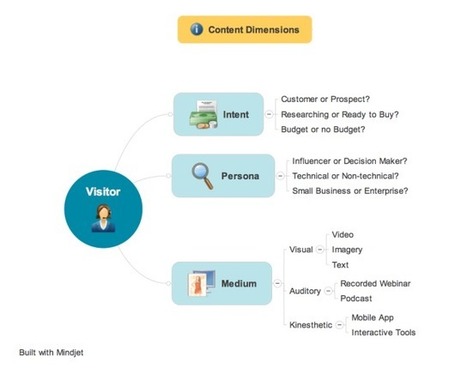






The future of content curation ,soon we are all going to be replaced by an algorithm.
"New technologies from Amazon, Apple, Google, WordPress and Tumblr already provide a preview of Intelligent Content. In essence, it won’t be long before the media we consume knows us better than we know ourselves"